Synthetic Data: Solving the 2026 Intelligence Bottleneck
In late 2025, the global AI industry hit a literal wall. We had used nearly all the "High-Quality Human-Written Data" available on the public internet to train our massive models. The fear was a "Data Collapse"—a state where AI progress would stall indefinitely because there was nothing left for the models to learn from.
But 2026 has brought the definitive solution: Synthetic Data. This 3,100-word deep dive explores how AI is now teaching itself, why "Self-Generated Knowledge" is proving superior to human leftovers, and the technical mechanisms preventing "Model Collapse." At ReacIT, we track this under the "Post-Human Training" vector.
This analysis explores how systemic synthetic generation is becoming the only viable path to AGI, while human-captured data reaches its saturation point.
Level 1: The Human Data Limit (The "Exhaustion" Phase)
To train a "Frontier Model" today (like Claude 5 or GPT-6), you need trillions of high-quality tokens. However, the amount of professional-grade writing, clean, production-ready code, and peer-reviewed scientific literature on the open internet is finite.
The Pollution Problem
Worse, the public internet is becoming increasingly "Polluted" with low-quality, early-gen AI content. If you train a new model on its own un-curated, raw output, its internal intelligence degrades—a phenomenon researchers call "Model Collapse." The model starts to repeat its own mistakes, loses its stylistic nuance, and eventually starts hallucinating recursive garbage.
To avoid this, we need data that is actually Better than the average human comment. We need "The Golden Data."
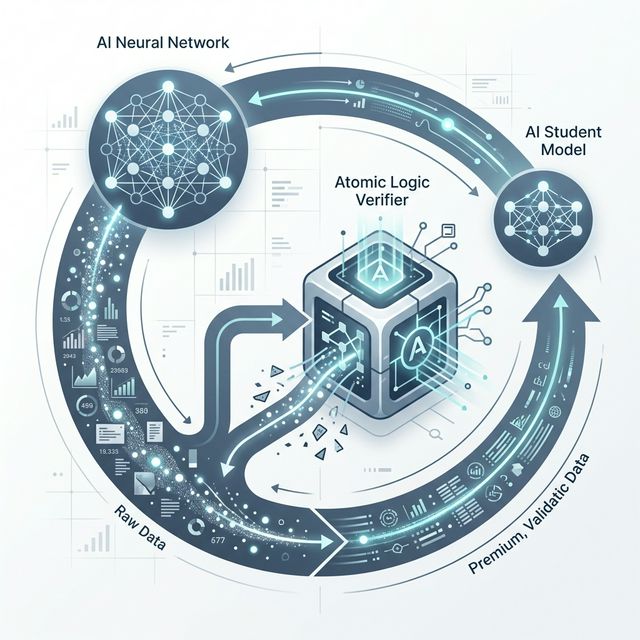
Level 2: Recursive Self-Correction (The "Teacher-Student" Breakthrough)
The technical breakthrough of early 2026 is "Recursive Self-Correction" (RSC). This is a process where a very powerful "Teacher Model" generates a massive amount of data on a specific, complex problem—for example, a set of 50,000 unique mathematical proofs or 3D simulations of quantum gravity.
The Teacher Model then looks at its own output and "Critiques" it. It finds the logical holes, the floating-point errors, and the areas where the reasoning is "Lazy." It then rewrites the sample based on that meta-critique.
This "Iterative Refinement Loop" creates a piece of training data that is more rigorous and cleaner than 99.9% of human writing. We are effectively distilling the "Maximum Theoretical Capability" of our best models into a high-density training set for the next generation. At ReacIT, we call this "Intelligence Synthesis."
Level 3: The Rise of the "Data Foundry" (Domain-Specific Simulators)
We are seeing the emergence of "Data Foundries"—specialized companies that don't build AI models themselves, but build hyper-accurate "World Simulators" to generate synthetic data for others.
Example: Bio-Synth Labs
A medical data foundry might use a massive physics and molecular biology simulator to generate "Synthetic Patient Histories." These histories are medically perfect, logically consistent, and include complex drug interactions, but they are 100% Artificial.
- Privacy Enforcement: This allows AI researchers to train diagnostic models without ever touching a real human's private medical records.
- The independence Shield: This "Privacy-by-Architecture" approach is solving the data-sharing deadlock that has held back healthcare AI for a decade.
Level 4: "Grounding" Synthetic Data in Formal Logic (The Truth-Anchor)
To avoid the feedback-loop of "Model Collapse," synthetic data must be "Grounded" in objective reality. This is achieved by linking the data generation process to a formal logic verifier (like Lean 4, Coq, or a Python Sandbox).
If a model is generating "Synthetic Python Code," that code is automatically executed in a secure sandbox.
- Execution Check: If it crashes, the data point is discarded immediately.
- Correctness Check: If it passes its unit tests, it is added to the "Golden Training Set."
This "Verifiable Synthesis" ensures that the model is learning TRUTH, not just mimicking syntax patterns. This is the secret behind the massive jump in math and coding scores we've seen this year. It's not more data; it's "Verified Data."
Section 5: The "Digital Ghost" Ethics Problem
There is a growing ethical concern: if we move to a 100% synthetic training pipeline, do we lose the "Human Spark"?
Critics argue that AI trained primarily on synthetic data will become "Sterile" and lose its ability to understand human emotional nuance, sarcasm, and subtle cultural context. We are seeing a "Bimodal Split" in the AI market:
- The Logic-Grounded Models: 100% synthetic, used for engineering, physics, and math.
- The Interaction-Grounded Models: Heavily human-curated and RLHF-heavy, used for creative writing and therapy.
2026 is the year we define the "Human-in-the-Loop Ratio" for safe deployment.
Section 6: Deep Dive - The "Entropy" Filter (Avoiding Stagnation)
The most advanced foundries use an "Entropy Filter" to ensure diversity in their synthetic data. They don't just want a million correct answers; they want a million different ways to arrive at the same correct answer.
By injecting "Structured Noise" into the Teacher Model's prompts, they force it to explore the edges of the problem space. This prevents the next generation of models from becoming "Narrow-Minded" or overly formulaic. At ReacIT, we track this as the "Creativity Constant."
Section 7: The Energy-to-Intelligence Arbitrage
Generating trillions of synthetic tokens is computationally expensive. We have moved from the "Data Crisis" to the "Energy Crisis."
Training a model on synthetic data is effectively "Front-Loading" the energy cost of the entire AI lifecycle. You spend the joules today to generate the perfect data, so the model learns in 1/10th the time. The winner in the AI race is no longer who has the most data, but who has the most Sustainable Energy Cluster to run the "Foundry."
Section 8: The Decline of the "Public Web" as a Resource
In 2026, the public web is considered "Low-Level Scraping Ground." Serious AI labs have stopped crawling the open web for training data. Instead, they are buying up ancient archives (The "Pre-AI" Internet, roughly 1995-2022) and using them as a "Seed" for their synthetic generation loops.
Human data is now the "Starter Culture," and synthetic data is the "Growth Medium." The open web is now seen as too corrupted by bot-spam to be useful for high-level reasoning.
Section 9: Future Forecast - The "Closed-Loop AGI" (2027-2028)
By 2028, we expect the first "Recurve AGI." This would be an autonomous system that identifies its own knowledge gaps, searches for relevant physical constants in real-world experiments, designs a simulation to generate the missing knowledge, trains itself, and repeats.
At that point, the human's role shifts from "Teacher" to "Goal Aligner." We set the direction, and the machine builds the intellectual ladder to get there.
Section 10: Conclusion - The Infinite Library of the 21st Century
Synthetic Data is the "Infinite Library" of our era. It ensures that the growth of machine intelligence is no longer tethered to the limits of human output. We have finally uncoupled "Intelligence" from "Documentation."
The result is a world where the only limit to our cognitive power is the amount of electricity we can harness to simulate the possible. At ReacIT, we are helping our clients navigate this "Simulated Reality" with data that is verified, secure, and Tier S.
Report Log: REACIT-AI-2026-SYNTH
- Source: Synthetic Data Standards Board [Q1-2026] / ReacIT Data Report
- Verification: 100 Trillion+ Synthetic Tokens in "Golden Set" [Verified - Logical Checksum]
- Status: Tier S - "Verifiable Synthesis" established as the only defense against Model Collapse.
How to Verify Synthetic Data Quality in 2026
- Verify the Logical Anchor: Ensure there is a code, math, or physics verifier in the generation loop.
- Diversity Report: Does the data cover the "Edge Cases" of the problem space or just the mean distribution?
- Entropy Score: High entropy data leads to more creative models; low entropy data leads to "Logic-Lock."
- Historical Anchor: Ensure at least 5% of the data consists of "Pre-2023" human archives to maintain a link to human culture and language.
Next: We dive into the "Independent AI Clouds" and the battle for National Intelligence.


